预热
本文以X86架构32位系统为对象讲述Linux的内存管理方式。
Linux 的虚拟内存管理有几个关键概念:
- 每个进程都有独立的虚拟地址空间,进程访问的虚拟地址并不是真正的物理地址;
- 虚拟地址可通过每个进程上的页表(在每个进程的内核虚拟地址空间)与物理地址进行映射,获得真正物理地址;
- 如果虚拟地址对应物理地址不在物理内存中,则产生缺页中断,真正分配物理地址,同时更新进程的页表;如果此时物理内存已耗尽,则根据内存替换算法淘汰部分页面至物理磁盘中。
Linux进程虚拟内存结构
Linux程序在辅存中存储的时候分为代码段,数据段,未初始化数据段三部分,在使用nm工具下可以看到这三部分数据短对应的符号表示分别为T或t,D或d,B或b,大些表示这个符号是外部(external)符号,小写表示符号是本地符号。程序在运行的时候多出了四个区域:堆(heap),栈(stack),文件映射区域,内核虚拟空间。
- 代码段: 存放CPU执行的机器指令。通常代码区是共享的,即其它执行程序可调用它。假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一个代码段。该部分内存只能读不能写。
- 数据段:存放已初始化的全局变量,静态变量(包括全局和局部的),常量。static全局变量和static函数只能在当前文件中被调用。
- 未初始化数据区(uninitializeddata segment,BSS):存放全局未初始化的变量。BSS的数据在程序开始执行之前被初始化为0或NULL。
- 堆段:用于存放进程运行中被动态分配的内存段,位于BSS和栈中间的地址位。由程序员申请分配(malloc)和释放(free)。堆是从低地址位向高地址位增长,采用链式存储结构。频繁地malloc/free造成内存空间的不连续,产生碎片。当申请堆空间时库函数按照一定的算法搜索可用的足够大的空间。因此堆的效率比栈要低的多。
- 栈区:由编译器自动释放,存放函数的参数值,局部变量等。每当一个函数被调用时,该函数的返回类型和一些调用的信息被存储到栈中。然后这个被调用的函数再为它的自动变量和临时变量在栈上分配空间。每调用一个函数一个新的栈就会被使用。栈区是从高地址位向低地址位增长的,是一块连续的内在区域,最大容量是由系统预先定义好的,申请的栈空间超过这个界限时会提示溢出,用户能从栈中获取的空间较小。
- 文件映射区:如动态库,共享内存等映射物理空间的内存,一般是mmap函数所分配的虚拟内存空间。
- 内核虚拟空间:内核虚拟空间是用户代码不可见的区域,由内核来管理(业表就存放于此)
下图是典型X86系统的虚拟内存空间分配图(来自《深入理解计算机系统》)
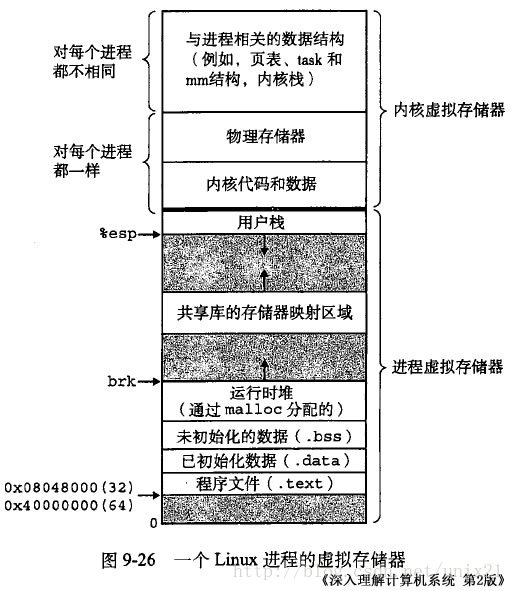
32位系统中有4G的地址空间:
其中0x8048000~0xbfffffff是用户空间,0xc0000000~0xffffffff是内核空间,包括内核代码、内核数据和与进程相关的数据结构(如页表,内核栈)等。另外,%esp执行栈顶,忘低地址方向变化;brk/sbrk函数控制堆顶_edata往高地址方向变化。
地址相关概念
1. 物理地址(physical address)
物理内存,真实存在的插在主板内存槽上的内存条的容量的大小.
内存是由若干个存储单元组成的,每个存储单元有一个编号,这种编号可唯一标识一个存储单元,称为内存地址(或物理地址)。我们可以把内存看成一个从0字节一直到内存最大容量逐字节编号的存储单元数组,即每个存储单元与内存地址的编号相对应。
2. 虚拟内存(Virtual memory)(也叫虚拟存储器)
虚拟内存地址就是每个进程可以直接寻址的地址空间,不受其他进程干扰。每个指令或数据单元都在这个虚拟空间中拥有确定的地址。
虚拟内存就是进程中的目标代码,数据等虚拟地址组成的虚拟空间
虚拟内存不考虑物理内存的大小和信息存放的实际位置,只规定进程中相互关联信息的相对位置。每个进程都拥有自己的虚拟内存,且虚拟内存的大小由处理机的地址结构和寻址方式决定。
比如32位机器可以直接寻址4G空间,意思是每个应用程序都有4G内存空间可用。
3. 逻辑地址(logical address)
源程序经过汇编或编译后,形成目标代码,每个目标代码都是以0为基址顺序进行编址的,原来用符号名访问的单元用具体的数据——单元号取代。这样生成的目标程序占据一定的地址空间,称为作业的逻辑地址空间,简称逻辑空间。
在逻辑空间中每条指令的地址和指令中要访问的操作数地址统称为逻辑地址。即应用程序中使用的地址。要经过寻址方式的计算或变换才得到内存中的物理地址。
很简单,逻辑地址就是你源程序里使用的地址,或者源代码经过编译以后编译器将一些标号,变量转换成的地址,或者相对于当前段的偏移地址。
逻辑地址是指由程序产生的与段相关的偏移地址部分。例如,你在进行C语言指针编程中,可以读取指针变量本身值(&操作),实际上这个值就是逻辑地址,它是相对于你当前进程数据段的地址,不和绝对物理地址相干。只有在Intel实模式下,逻辑地址才和物理地址相等(因为实模式没有分段或分页机制,Cpu不进行自动地址转换);逻辑也就是在Intel保护模式下程序执
4. 线性地址或Linux下也叫虚拟地址(virtual address)
这个地址很重要,也很不容易理解。分段机制下CPU寻址是二维的地址即,段地址:偏移地址,CPU不可能认识二维地址,因此需要转化成一维地址即,段地址*16+偏移地址,这样得到的地址便是线性地址(在未开启分页机制的情况下也是物理地址)。这样有什么意义呢?或者说这个一维地址的计算方法随便一个学计算机的人都知道,但是你真的理解它的意思吗?要想理解它的意思,必须要知道什么是地址空间,下文详述。
线性地址是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或者说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址可以再经变换以产生一个物理地址。若没有启用分页机制,那么线性地址直接就是物理地址。Intel 80386的线性地址空间容量为4G(2的32次方即32根地址总线寻址)。
跟逻辑地址类似,它也是一个不真实的地址,如果逻辑地址是对应的硬件平台段式管理转换前地址的话,那么线性地址则对应了硬件页式内存的转换前地址。
CPU将一个虚拟内存空间中的地址转换为物理地址,需要进行两步:首先将给定一个逻辑地址(其实是段内偏移量=),CPU要利用其段式内存管理单元,先将为个逻辑地址转换成一个线程地址,再利用其页式内存管理单元,转换为最终物理地址。
行代码段限长内的偏移地址(假定代码段、数据段如果完全一样)。应用程序员仅需与逻辑地址打交道,而分段和分页机制对您来说是完全透明的,仅由系统编程人员涉及。应用程序员虽然自己可以直接操作内存,那也只能在操作系统给你分配的内存段操作。
4.逻辑地址线性地址转换
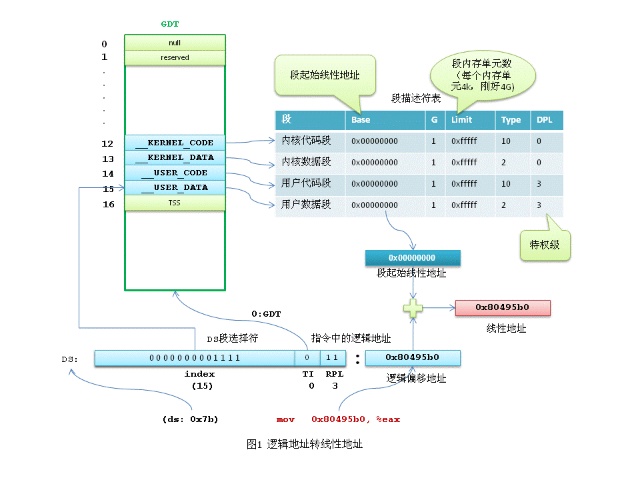
在32位机器下我们使用nm查看一个程序,可以看到类似0x80495b0地址的.Data段符号,这个内存地址就是一个逻辑地址,必须加上.Data数据段的基地址才能构成线性地址。也就是说0x80495b0这个是在.Data基地址段的一个偏移。
在x86保护模式下,段的信息(段基线性地址、长度、权限等)即段描述符占8个字节,段信息无法直接存放在段寄存器中(段寄存器只有2字节)。Intel的设计是段描述符集中存放在GDT或LDT中,而段寄存器存放的是段描述符在GDT或LDT内的索引值(index)。
这样的情况下Linux只用到了GDT,不论是用户任务还是内核任务,都没有用到LDT。GDT的第12和13项段描述符是 __KERNEL_CS 和\_KERNEL_DS,第14和15项段描述符是 \_USER_CS 和\_USER_DS。内核任务使用\_KERNEL_CS 和\_KERNEL_DS,所有的用户任务共用\_USER_CS 和\_USER_DS,也就是说不需要给每个任务再单独分配段描述符。内核段描述符和用户段描述符虽然起始线性地址和长度都一样,但DPL(描述符特权级)是不一样的。\_KERNEL_CS 和\_KERNEL_DS 的DPL值为0(最高特权),\_USER_CS 和\__USER_DS的DPL值为3。
内核中的是内核数据段和内核代码段。include/asm-i386/segment.h
#define GDT\_ENTRY\_DEFAULT\_USER\_CS
#define _\_USER\_CS (GDT\_ENTRY\_DEFAULT\_USER\_CS * 8 + 3)
#define GDT\_ENTRY\_DEFAULT\_USER\_DS
#define _\_USER\_DS (GDT\_ENTRY\_DEFAULT\_USER\_DS * 8 + 3)
#define GDT\_ENTRY\_KERNEL_BASE
#define GDT\_ENTRY\_KERNEL\_CS (GDT\_ENTRY\_KERNEL\_BASE+ 0)
#define _\_KERNEL\_CS (GDT\_ENTRY\_KERNEL_CS * 8)
#define GDT\_ENTRY\_KERNEL\_DS (GDT\_ENTRY\_KERNEL\_BASE+ 1)
#define _\_KERNEL\_DS (GDT\_ENTRY\_KERNEL_DS * 8)
把其中的宏替换成数值,则为:
#define _\_USER\_CS 115 [00000000 1110 0 11]
#define _\_USER\_DS 123 [00000000 1111 0 11]
#define _\_KERNEL\_CS 96 [00000000 1100 0 00]
#define _\_KERNEL\_DS 104 [00000000 1101 0 00]
方括号后是这四个段选择符的16位二制表示,它们的索引号和T1字段值也可以算出来了
_\_USER\_CS index= 14 T1=0
_\_USER\_DS index= 15 T1=0
_\_KERNEL\_C index= 12 T1=0
_\_KERNEL\_DS index= 13 T1=0
T1均为0,则表示都使用了GDT,再来看初始化GDT的内容中相应的12-15项(arch/i386/head.S):
.quad 0x00cf9a000000ffff /\* 0x60 kernel 4GB code at 0x00000000 \*/
.quad 0x00cf92000000ffff /\* 0x68 kernel 4GB data at 0x00000000 \*/
.quad 0x00cffa000000ffff /\* 0x73 user 4GB code at 0x00000000 \*/
.quad 0x00cff2000000ffff /\* 0x7b user 4GB data at 0x00000000 \*/
按照前面段描述符表中的描述,可以把它们展开,发现其16-31位全为0,即四个段的基地址全为0。 这样,给定一个段内偏移地址,按照前面转换公式,0 + 段内偏移,转换为线性地址,可以得出重要的结论,“在Linux下,逻辑地址与线性地址总是一致的,即逻辑地址的偏移量字段的值与线性地址的值总是相同的。
用gdb调试程序的时候,用info reg 显示当前寄存器的值:
cs 0x73 115
ss 0x7b 123
ds 0x7b 123
es 0x7b 123
可以看到ds值为0x7b, 转换成二进制为 00000000 01111011,TI字段值为0,表示使用GDT,GDT索引值为 01111,即十进制15,对应的就是GDT内的__USER_DATA 用户数据段描述符。
从上面可以看到,Linux在x86的分段机制上运行,却通过一个巧妙的方式绕开了分段。
Linux主要以分页的方式实现内存管理。
CPU分页式内存管理
CPU的页式内存管理单元,负责把一个线性地址,转换为物理地址。从管理和效率的角度出发,线性地址被分为以固定长度为单位的组,称为页(page),例如一个32位的机器,线性地址最大可为4G,可以用4KB为一个页来划分,这页,整个线性地址就被划分为一个tatol_page[2^20]的大数组,共有2的20个次方个页。这个大数组我们称之为页目录。目录中的每一个目录项,就是一个地址——对应的页的地址。 另一类“页”,我们称之为物理页,或者是页框(frame)、页桢的。是分页单元把所有的物理内存也划分为固定长度的管理单位,它的长度一般与内存页是一一对应的。 这里注意到,这个total_page数组有2^20个成员,每个成员是一个地址(32位机,一个地址也就是4字节),那么要单单要表示这么一个数组,就要占去4MB的内存空间。为了节省空间,引入了一个二级管理模式的机器来组织分页单元。文字描述太累,看图直观一些:
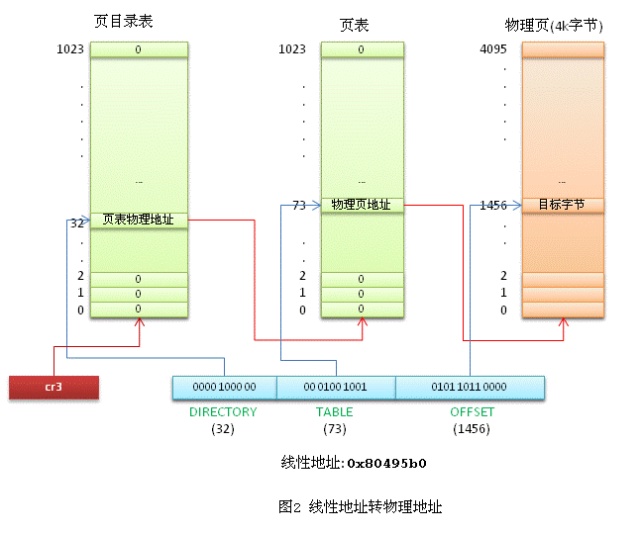
为了实现每个任务的平坦的虚拟内存,每个任务都有自己的页目录表和页表。
在调度到一个进程的时候,进程的页目录地址放在CPU的cr3寄存器中,是进行地址转换的开始点。
每一个32位的线性地址被划分为三部份,面目录索引(10位):页表索引(10位):偏移(12位) 依据以下步骤进行转换:
(1)从cr3中取出进程的页目录地址(操作系统负责在调度进程的时候,把这个地址装入对应寄存器);
(2)根据线性地址前十位,在数组中,找到对应的索引项,因为引入了二级管理模式,页目录中的项,不再是页的地址,而是一个页表的地址。(又引入了一个数组),页的地址被放到页表中去了。
(3)根据线性地址的中间十位,在页表(也是数组)中找到页的起始地址;
(4)将页的起始地址与线性地址中最后12位相加,得到最终我们想要的葫芦;这个转换过程,应该说还是非常简单地。
那么这个分页二级寻址是如何节省页表所占用的内存的呢?下面我们来计算一下。
原本不是用二级页表的时候:一个页面2^12字节大小,则2^32字节的内存被分为2^20个页,需要 2^20 * 4大小的页表,则占用了4M的内存。所以要求每个进程需要一个4M的页表才能完全表示4G内存的所有页。
使用了二级寻址模式,一个叶目录大小为2^10 * 4 = 4K Byte大小,其每一项对应一个页表,一个页表的大小为2^10 * 4 = 4K Byte,如果页目录全部被填满,则会消耗2^10(页表个数) * 4K Byte(页表大小) + 4K(页目录大小) =4M + 4K Byte。最后反而比一级模式使用了更大的内存。 但一个进程往往不会使用这么多内存,页目录很多项都没有使用,则可以不用产生很多没有使用的页表,以此来减少页表所占用的内存。
Linux的内存管理
原理上来讲,Linux只需要为每个进程分配好所需数据结构,放到内存中,然后在调度进程的时候,切换寄存器cr3,剩下的就交给硬件来完成了(事实上要复杂得多,在此只分析最基本的流程)。前面说了i386的二级页管理架构,不过有些CPU,还有三级,甚至四级架构,Linux为了在更高层次提供抽像,为每个CPU提供统一的界面。提供了一个四层页管理架构,来兼容这些二级、三级、四级管理架构的CPU。这四级分别为: 页全局目录PGD、页上级目录PUD、页中间目录PMD、页表PT。 整个转换依据硬件转换原理,只是多了二次数组的索引罢了,如下图:
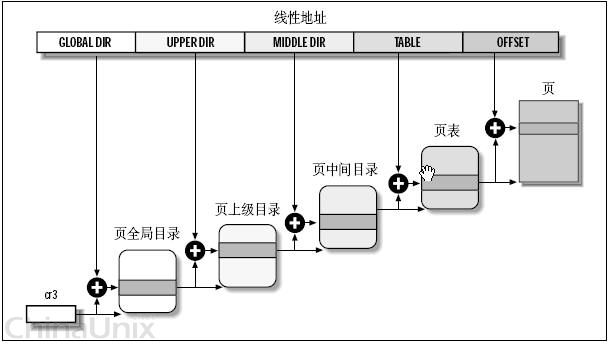
那么,对于使用二级管理架构32位的硬件,四级转换怎么能够协调地工作呢?嗯,来看这种情况下,怎么来划分线性地址吧!从硬件的角度,32位地址被分成了三部份;从软件的角度,由于多引入了两部份,也就是说,共有五部份。——要让二层架构的硬件认识五部份也很容易,在地址划分的时候,将页上级目录和页中间目录的长度设置为0就可以了。这样,操作系统见到的是五部份,硬件还是按它死板的三部份划分,也就共建了和谐计算机系统。 这样,虽说是多此一举,但是考虑到64位地址,使用四层转换架构的CPU,此时不再把中间两个设为0了,这样,软件与硬件再次共建了和谐计算机系统——抽像,强大呀! 例如,一个逻辑地址已经被转换成了线性地址,0x08147258,换成二制进是: 0000100000 0101000111 001001011000 内核对这个地址进行划分 PGD = 0000100000 PUD = 0 PMD = 0 PT = 0101000111 offset = 001001011000
现在来理解Linux高招,因为硬件根本看不到所谓PUD,PMD,所以,本质上要求PGD索引,直接就对应了PT的地址。而不是再到PUD和PMD中去查数组(虽然它们两个在线性地址中,长度为0,2^0 =1,也就是说,它们都是有一个数组元素的数组),那么,内核如何合理安排地址呢?从软件的角度上来讲,因为它的项只有一个,32位,刚好可以存放与PGD中长度一样的地址指针。那么所谓先到PUD,到到PMD中做映射转换,就变成了保持原值不变,一一转手就可以了。这样,就实现了“逻辑上指向一个PUD,再指向一个PDM,但在物理上是直接指向相应的PT的这个抽像,因为硬件根本不知道有PUD、PMD这个东西”。 然后交给硬件,硬件对这个地址进行划分,看到的是:页目录= 0000100000 PT = 0101000111 offset = 001001011000 嗯,先根据0000100000(32),在页目录数组中索引,找到其元素中的地址,取其高20位,找到页表的地址,页表的地址是由内核动态分配的,接着,再加一个offset,就是最终的物理地址了。
参考文章:
http://blog.csdn.net/hguisu/article/details/6152921 http://blog.csdn.net/do2jiang/article/details/4512417 http://blog.csdn.net/wxzking/article/details/5905214 http://www.360doc.com/content/14/1025/15/15064667_419739905.shtml